![[object Object]](/static/SBI-new-3f05b8e8a65d5a738bcbf2b4b08ae8c3.svg)
![[object Object]](/static/HDFC-new-bbc46138c322f4e8beb5ef76c57a6aff.svg)



 All Tech Blogs
All Tech BlogsEngineering
All Tech Blogs



In the dynamic landscape of modern technology, data-driven decision-making is pivotal to an organization’s success. At PhonePe, this principle is not just a mantra but a fundamental aspect of our operations. To gain insights, monitor performance, and respond to events in near-real-time, we rely on a steady stream of data generated by our services. These data points, or events, encompass a wide range of information, from user interactions and system metrics to transaction records. Yet, efficiently managing this colossal influx of data presents a formidable challenge.
This is where Kafka comes in. Kafka, a distributed streaming platform, has become the backbone of our data infrastructure, enabling us to seamlessly handle the staggering flow of information.
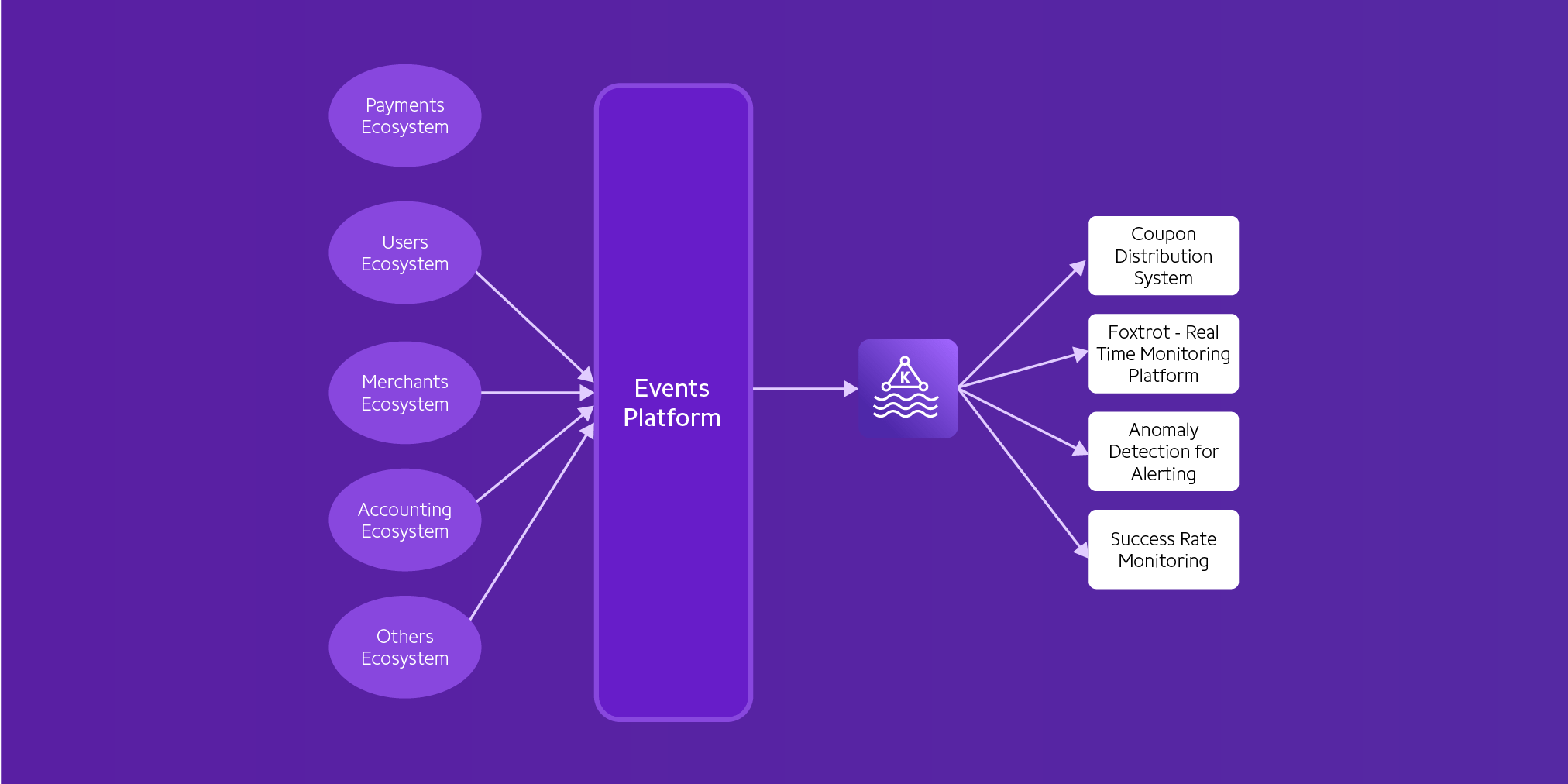
At PhonePe, we have entrusted Kafka with the critical role of ferrying approximately 100 billion events per day—a monumental task that grows exponentially year after year. Today, an ever-growing number of our engineering teams are harnessing Kafka in their applications.
PhonePe’s approach involved implementing a two-step architecture for handling data events. In this setup, the core concept was straightforward: a client library, utilized by our development teams, took charge of writing events to storage using BigQueue. Concurrently, a distinct executor process, aptly named the “Ingestor,” operated within the client library framework. This Ingestor was responsible for reading the stored events from the disk and subsequently transmitting them to the IngestionService. Once in the hands of the IngestionService, the data was diligently channeled into Kafka, effectively orchestrating the entire event ingestion process.
The client library handles file rotation, writes file locations, and can also write directly to the IngestionService in sync for specific use cases. The Ingestor is responsible for reading files, sending events to IngestionService, tracking file offsets, and managing file deletion.
This 2-step logging architecture offers various advantages, such as separating operational concerns from development teams. The lightweight Ingestor, integrated into the client library, operates across all Docker containers in their infrastructure and efficiently pushes events to Kafka through IngestionService, managed by the platform team.
Beyond enhancing resilience, the architecture simplifies API usage for producers who need to send events without Kafka expertise. Writing to disks bolsters resilience in scenarios like connectivity or Kafka issues. However, this design introduces increased latency to ensure resiliency and flexibility, with 99-percentile latency under 3s and 75-percentile under 2s for analytics data. For low-latency needs (< 1s), direct access to IngestionService through the client library is available for critical, time-sensitive applications. This approach strikes a balance between simplicity (95% of use cases) and flexibility for sub-second latency (< 100 ms) requirements.
Let us now delve into the innovative approaches that have allowed us to navigate the landscape of data-driven insights using Kafka’s infrastructure.
At the outset of our Kafka journey, our strategy was to maintain a single Kafka Cluster per data center. However, as time progressed, we recognized the need for a more refined approach. In response to our company’s significant growth and the proliferation of consumer applications in recent years, we adopted a dual Kafka cluster strategy aimed at segregating write and read workloads.
This evolution was driven by the imperative to shield our write workload from the potential impacts of read operations. As our organization expanded in scale and complexity, this separation became essential to maintain the efficiency and resilience of our Kafka infrastructure.
Determining the right time to scale a Kafka Cluster became our next challenge. We aimed to create a comprehensive metric that assessed cluster capacity based on multiple resource metrics, comparing each to an upper limit representing our operational threshold. This percentage value, calculated as the current resource metric/upper limit, was obtained for each resource and the maximum of these percentages represented the overall cluster capacity. This approach simplified the capacity evaluation to a single number, revealing the most significant resource constraint at any given moment.
This capacity assessment method also proved valuable for scaling down clusters when needed.
Initially, we provisioned Kafka clusters with two disks per node. However, as our operations expanded, we encountered performance limitations primarily related to disk I/O, while other key metrics remained well within acceptable boundaries. To address this issue, we decided to increase the number of disks per Kafka node, moving from 2 to 4 to 8. This adjustment significantly improved the utilization of crucial metrics and allowed our Kafka clusters, with the same number of nodes, to efficiently handle increased workloads.
As our data continued to grow, we reached a point where we questioned the necessity of the data being sent. It was apparent that the Events Platform had turned into a repository for data, much of which wasn’t contributing value. To address this, we borrowed a strategy from cloud providers: assigning a utilization value to usage and attributing it to users. The core idea was to make development teams responsible for their Kafka usage and accountable for the associated costs.
For Kafka, quantifying a team’s usage involved choosing a suitable metric for cost allocation, and we opted for bytes sent, deliberately excluding consumer usage to avoid penalizing data consumers. We also assigned a team to each request from Ingestor to IngestionService using JSON Web Tokens, simplifying the cost attribution process.
Implementing this approach empowered teams to assess their data needs, encouraging a shift in mindset towards cost management. It motivated proactive cost management and responsible use of company resources. In the future, we aim to expand this cost attribution effort company-wide for various systems and development teams.
In conclusion, Apache Kafka stands as a highly scalable and robust software, presenting relatively manageable challenges at scale. Notably, the primary hurdles lie beyond the Kafka software itself and center around:
As we embrace an increasingly interconnected future, we remain committed to pushing the boundaries of what is achievable in the realm of digital payments. We eagerly anticipate sharing updates on these initiatives in the months ahead.