![[object Object]](/static/SBI-new-3f05b8e8a65d5a738bcbf2b4b08ae8c3.svg)
![[object Object]](/static/HDFC-new-bbc46138c322f4e8beb5ef76c57a6aff.svg)



 All Tech Blogs
All Tech BlogsArchitecture
All Tech Blogs



In this article, we will discuss the optimizations we did to reduce the footprints of our Elasticsearch. We optimized write throughput and reduced disk storage by leveraging query patterns and tuning indexing and doc_values for fields in elastic search.
Problem Statement
At PhonePe, we manage huge Elasticsearch data clusters that are both expensive and challenging to maintain. Over time, our analytics system has grown to become the largest footprint in the PhonePe ecosystem, storing approximately 1.6 petabytes of data across 1,500 data nodes. Managing such large clusters of data was proving to be a daunting task.
Analysis
In Elasticsearch, the disk and CPU resources required to index and store a document are directly correlated with the number of fields it contains, particularly those that are queryable and retrievable.
We leveraged Elasticsearch’s disk usage API to gain insights into the actual storage utilized by various components.
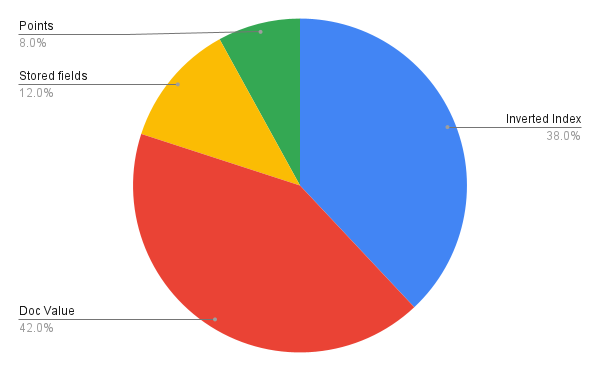
Elasticsearch Storage analysis —
When you index a document into Elasticsearch, the original document (without any analyzing or tokenizing) is stored in a special field called _source.But since we have Hbase for storing original documents we have disabled the source. We only store metadata fields in Elasticsearch, with all other fields marked as _store: false. Consequently, we neither stored data fields nor the actual _source in Elasticsearch. Upon analysis, the actual storage metrics for most of the indices appeared as follows:
Optimizations
Given that the system is heavily write-intensive, optimizing storage is possible by refining the indexing and storage logic in Elasticsearch. All fields have ‘index’ and ‘doc_values’ set to true by default. By optimizing these settings, we can reduce resource usage and enhance the overall efficiency of data storage and retrieval.
Query Auditing —
Using dynamic mappings in a client-driven schema can be challenging, as it allows clients to easily add new fields, resulting in an increasing number of fields over time. We reached over 2,000 fields for multiple clients, with many fields not being queried frequently. To address this, we implemented a query field auditing system on the application side to monitor the frequency and types of queries for each field.
The results were quite surprising: many nested fields, long text fields, and timestamps were infrequently queried. Our analysis revealed that only 25% of the fields were queried in the last six months.
Disabling Indexing and Doc Values
Indexing fields facilitate fast queries by maintaining an inverted index during data ingestion. This inverted index enables queries to quickly lookup search terms in a uniquely sorted list and immediately access the list of documents containing those terms, thereby powering FILTER queries efficiently. However, inverted indexes require significant storage. For fields that are not queried within a specific period, we can disable their indexing to save storage space.
Similar to indexing, Elasticsearch uses doc_values to enable sorting, aggregations, and access to field values in scripts, including operations like SUM, AVG, UNIQUE, and MAX. Doc_values are on-disk data structures built during document indexing, facilitating audited data access patterns. They store the same values as the _source of document but in a column-oriented format, which is much more efficient for sorting and aggregations. For fields that do not require sorting, aggregation, or script access, we can disable doc_values to save disk space.
Using templates
Elasticsearch Index Templates provide a way to set up well-defined mappings, settings, and aliases for one or more indices that match a specific pattern. However, as it is not possible to modify a field’s indexing or doc_values properties at runtime, we make use of query metadata to create index templates. In our case, we follow the day-wise indexing strategy as explained in Part ¹. Alternatively, one can also reindex the data into a new index with the updated mappings. The index templates store field-wise indexing and doc_values configurations, which are then applied while creating a new index the following day. The same templates are used to both enable and disable indexing or doc_values.
Impact
By reducing the number of indexed fields, we can save significant storage, which varies depending on client and query patterns. Additionally, this optimization reduces CPU utilization and write latencies per document. Disabling indexing for approximately 40% of our fields led to a 30% improvement in write latencies and increased indexing throughput per node.
Storage
Overall, we achieved a 45% reduction in the average size of events from 850 bytes to 450 bytes after implementing changes to indexing and doc_values leading to an overall reduction in per-day data from 60 TB to 40 TB.
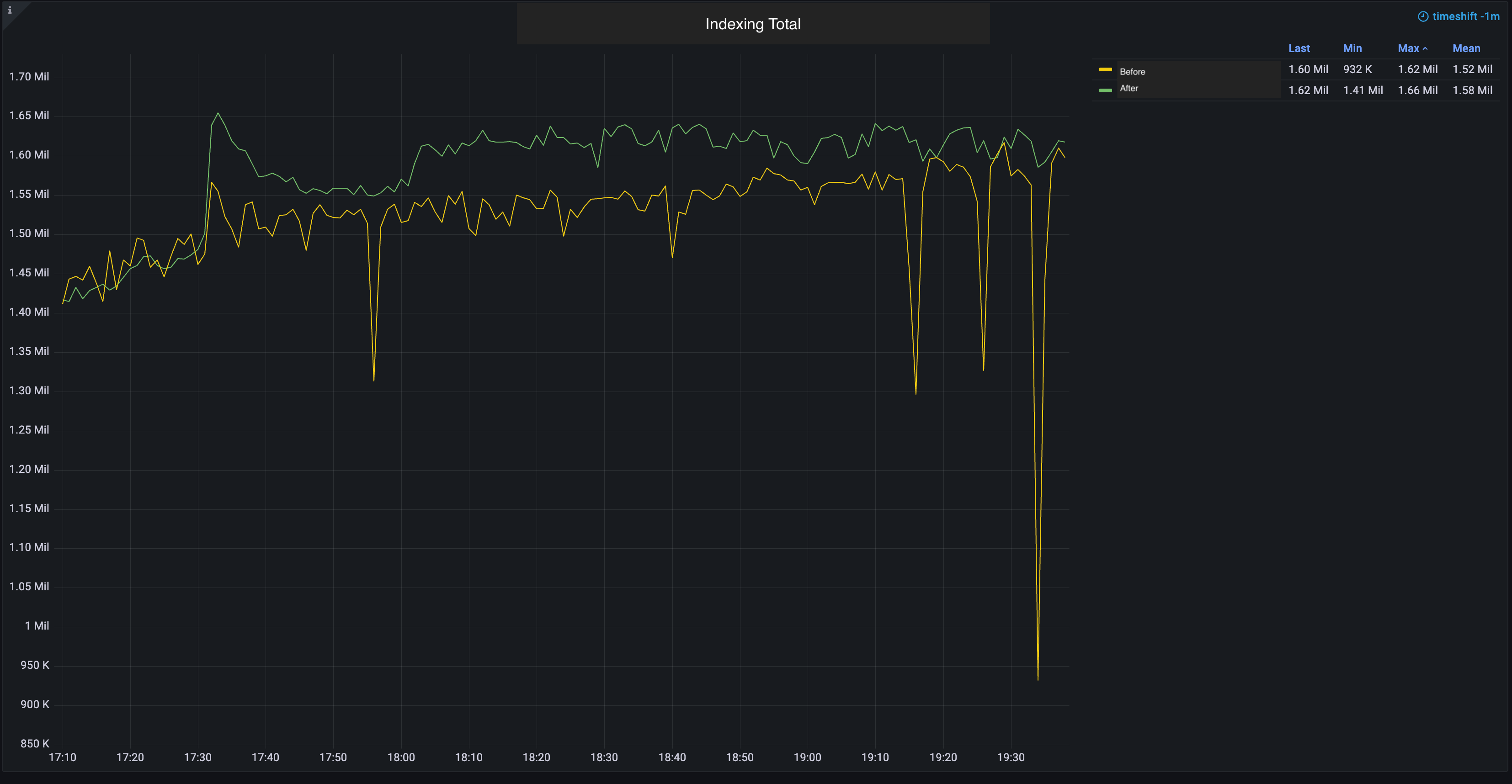
Indexing Speed
We observed an approximately 30% increase in the average indexing rate across the cluster.
Before releasing this feature, the maximum indexing rate per second was around 874K after the changes, it increased to 1.14M, which bumped up the document ingestion rate.
Latency/CPU Improvement
With reducing the number of indexing fields, computation to form a reverse index is also reduced. We are observing a 50% reduction in mean latencies from 1.05s to 500ms for ingestion which will also help in CPU usage reduction.
In our production environment, by disabling indexing and doc_values based on query audits, we have seen a 45% reduction in our data footprint. This optimization is expected to reduce our overall cluster size from 1,500 nodes to approximately 900 nodes.
In addition to storing fields and the _source, indexing and doc_values consume a significant amount of storage. To minimize data footprint, we can disable indexing and doc_values for fields that are not frequently queried. This approach not only reduces storage requirements but also decreases CPU usage during ingestion. Even for fields that are rarely queried, disabling indexing can be beneficial, as FILTER queries can still be served using doc_values
However, caution is required when disabling indexing or doc_values for fields, as data ingested during this period will not have the corresponding inverted index or doc_value mappings and, therefore, won’t be queryable even if indexing/doc_values are re-enabled later. Given our system’s small TTL, data is quickly replaced, mitigating some risks. For future use cases, we are planning to backfill data from HBase or reindex using the _source (if enabled) to support reintroducing indexing/doc_values for historical data.