![[object Object]](/static/SBI-new-3f05b8e8a65d5a738bcbf2b4b08ae8c3.svg)
![[object Object]](/static/HDFC-new-bbc46138c322f4e8beb5ef76c57a6aff.svg)



 All Tech Blogs
All Tech BlogsArchitecture
All Tech Blogs



In the previous article, I provided a concise overview of PhonePe’s Elasticsearch architecture and outlined the diverse strategies employed to efficiently scale our cluster in order to manage millions of writes.
In this article, I will look into our cluster configuration and settings, alongside presenting performance results from a range of load tests.
Most of the PhonePe infrastructure is hosted on self-managed data centre. Our Elasticsearch data nodes are run on Intel Servers.
Over the years, we have changed our data node configuration as below
Data nodes are provisioned as 4 VMs on a dedicated BareMetal. So, these 800+ data nodes are provisioned atop 200+ BareMetal
In the upcoming section of the article, I’ll discuss a range of performance comparisons and the challenges we’ve faced throughout the years.
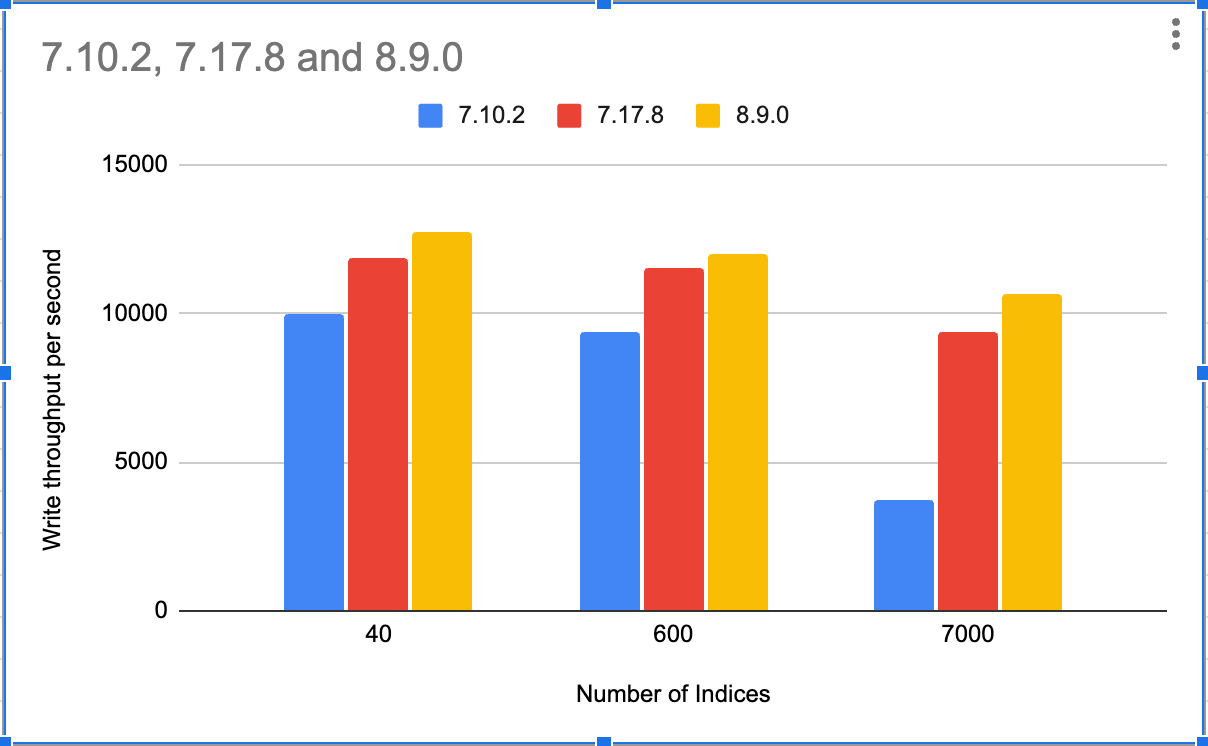
We encountered a major bug in Elasticsearch 7.10.2 version related to Authorisation which impacted the write throughput of the cluster. The impact was more severe when we had more indices in the cluster. For clusters having indices in single digits, impact was minimal.
You can see in below chart, the throughput drop was too steep in Elasticsearch 7.10.2
More details about the bug can be found here — https://github.com/elastic/elasticsearch/issues/67987
As per our load tests, we are seeing higher throughput in Elasticsearch 8.9.0 as compared to Elasticsearch 7.x versions. Will publish a detailed article at later point in time with full RCA of this performance difference
Below is the CPU utilisation graph of our 2 clusters with exactly the same workload but different Elasticsearch versions.
As per out load tests, VM based elasticsearch performance was better than process based elasticsearch. Unfortunately, we weren’t able to spend a lot of time to debug the reasoning for the same.
In the next part, we will discuss our algorithm which helps us decide which fields we should enable indexing and doc_values.