![[object Object]](/static/SBI-new-3f05b8e8a65d5a738bcbf2b4b08ae8c3.svg)
![[object Object]](/static/HDFC-new-bbc46138c322f4e8beb5ef76c57a6aff.svg)



 All Tech Blogs
All Tech BlogsMobile
All Tech Blogs



Have you ever used the PhonePe app to send money to a friend via their phone number? If you did, you’ve definitely come across the P2P flow. It’s one of the most important features of the PhonePe app and we want to make sure it’s a smooth experience.
This blog is a first in a series of blogs that elaborate on the improvements to the P2P flow on Android. This blog, in particular, touches upon how we analyse performance and the different methodologies we used.
After persistent effort on improving the chat flow, we reduced the latency by nearly ~50%. This blog series covers 6 different approaches we used to improve performance:
The P2P flow starts from clicking on the ‘To mobile’ icon on the PhonePe app home screen, which opens a chat roster. After selecting the specific chat from the roster, the user lands on the chat page and can initiate a payment. The flow ends when the user has completed a payment and sees the confirmation screen. Since this is a critical flow on the PhonePe app, our goal was to reduce the latency of the overall flow where possible.
The entire flow is divided into separate stages, and we measured the latencies of each stage. We measured system time (time taken by our app during the flow) separately from user time (time taken during user interactions). The former can be improved through pure engineering changes while the latter needs product/UX changes. On looking at past metrics, we decide to focus on the system time for mainly two stages:
1. Chat Display: Time taken to load the list of chats on chat roster
2. Display Message: Time taken to load chat page after selecting a chat / contact
All data for chats on the chat roster are stored offline in a local database, so it is critical to ensure our Db queries are fast.
We evaluated these queries using an in-house app performance monitoring system called Dash. It has a client library, and this library reports metrics to a backend analytics system. Although great external systems like Firebase and Sentry.io are available, Dash supports PhonePe’s scale and compliance requirements, and allows us to add custom capabilities quickly.
1. Identification of slow queries – Dash logs all the latent queries executed during a flow. Any query taking more than 50ms is marked as latent and is logged on Dash (in a dashboard).
2. Debugging slow queries – After identifying tables/views which are latent, we used SQLite “Explain query” to understand what happens during a query. It tells you whether index is being used or not, whether all rows were scanned or only a small subset of rows were scanned using index. With the help of DbBrowser we checked all the queries in this path. Please refer to https://www.sqlite.org/eqp.html to understand how Explain Query works.
We did find a few queries where indexing was missing, however, upon investigation, most of them looked fine, so there was barely any low-hanging fruit.
As we dug deeper, we found that many of the slow queries were caused by complex joins between multiple tables and views. These make the query heavy and leads to higher latency. Since this would require redesigning the database layer, we have parked this aside for the time being.
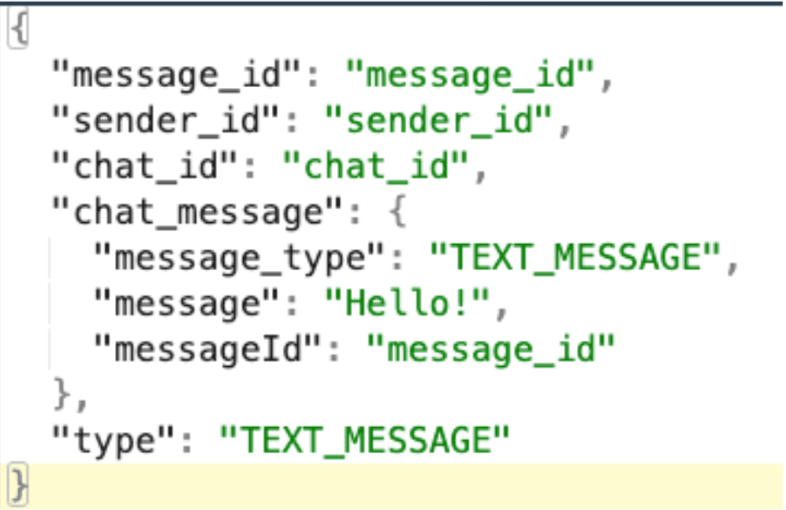
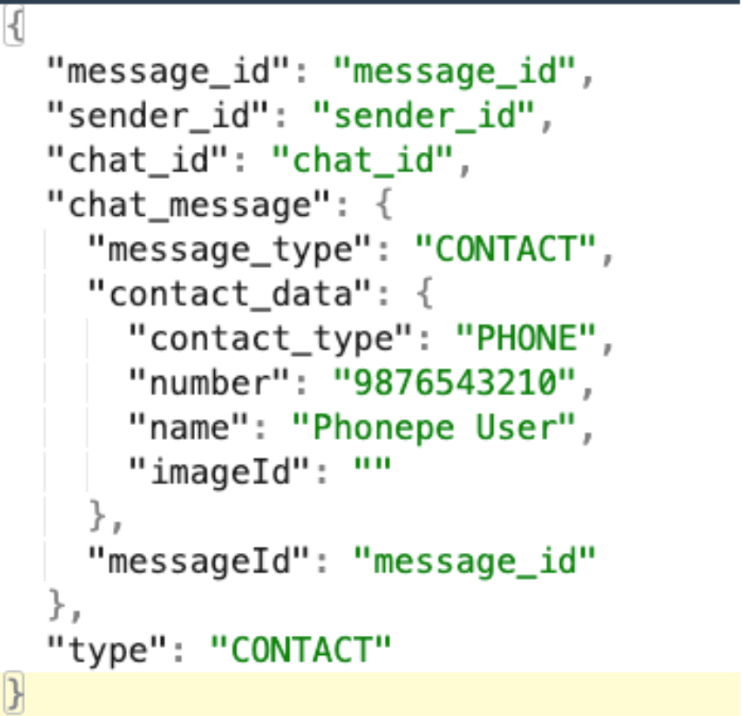
Dash highlighted that queries on the chat message table are slow, so we started looking into this. We saw that most of the time spent here was not on the Db query itself, but in deserializing JSON.
The payload of all messages of a chat are stored as JSON in the chat table. When we fetch messages, room converts these JSON into respective POJOs at runtime. And most of the delay came from deserializing the data.
It’s important to explain the JSON structure of our payloads:
Parsing such nested JSON is a relatively slow process since many types of messages exist. There are a lot of articles on optimizing GSON deserialization, so we decided to use a different deserializer or change the message structure. We did POCs for each approach and compared their impact.
1. We reorganized the message table into distinct tables for each type of card, alongside a meta table containing common properties such as message Id and message type. While reading data, we first retrieve a list of messages from the meta table, and subsequently fetch the specific message content from the corresponding individual table based on the message’s type and Id.
2. In this approach, we maintain the same structure of a meta table and distinct content tables for each message type. However, the key distinction lies in our data retrieval process. We create an SQL view by running joins between the meta table and individual message content tables. Queries are then executed on this unified view to retrieve the desired data.
3. Using a different deserialisation library for creating POJOs at runtime. Right now we are using the GSON and Kotlinx serialization library. We explored Moshi and Protobuf.
1. We understood that having separate tables and using a join query to fetch data was faster than the original GSON serialization. It was also faster than making two queries, first query to fetch meta data and then individual messages.
2. Moshi was faster than GSON.
3. Protobuf was significantly faster than GSON and almost as fast as separating tables. It has the added advantage of less maintenance (for additional tables), so we went ahead with this approach.
We released protobuf changes in September. To our surprise, we didn’t see an improvement in query times in production. After checking the data for a couple of weeks, we went back to the POC process. We realized that we missed a couple of things during our POC phase which resulted in a significant difference between JSON serialization and other approaches. In reality, the difference wasn’t as huge as we believed, which is why we didn’t see a difference in production.
1. We made changes in the existing chat message deserialization logic for the POC purpose. These changes actually degraded the original GSON deserialization time. Additionally, the numbers against which we made the comparison were not correct. Thus, other approaches showed better numbers against GSON deserialization time.
2. We didn’t consider the GSON caching mechanism. For a given JSON string, if the library took ~200 ms to deserialize it the first time, the second time it will take only 25 -35ms as it doesn’t use reflection for the second time. When we were doing the initial POC, we wrote a script that would kill the app, open it and log the deserialisation time. So the caching never came into picture. When we checked again, we found that the numbers were actually comparable to proto numbers.
In the end we didn’t get the expected improvements with Proto, so we went back to using GSON. We learned that if an object needs to be serialized only once during an app session then proto would be significantly faster, and we can consider that for different use cases.
Initially on the chat roster, we fetched the complete list of chats and forwarded this complete list to the recyclerview. If you open the chat roster on the PhonePe app you will see only 6-8 chat threads visible at a time.
If the recyclerview does not create UI elements for all items in the list, fetching a big list from db and then performing transformation on each item is wasted effort. And we repeat this operation whenever a new message comes in. Some users have more than 10000 chat threads, and would have a particularly bad experience. Pagination is a very common optimization option for such issues.
We used the android paging library for this effort. It improved the process by 30-33% at P90 (3-3.4 seconds down to 2-2.3s). The 2-seconds time is still higher than what we hope to achieve, but pagination was a low hanging fruit, that sets us for more complicated optimizations. Alas, you’ll have to wait for the next blog to know more!
We discussed three approaches.
1. Check your latent db queries. Use Explain query and to understand how the query is executed.
2. Proto is only better when deserialisation is happening once, but if the same object type is deserialized repeatedly, then GSON performance is similar. One can think of moving to Moshi as it is slightly better than GSON.
3. If the list is large but not all are used, then consider pagination. It will consume less resources and will improve the overall performance time.
These approaches collectively improve latency by 20%. In the next blog, we will cover more approaches that helped with another 30% (Spoiler alert – CPU profiling and thread pools)