![[object Object]](/static/SBI-new-3f05b8e8a65d5a738bcbf2b4b08ae8c3.svg)
![[object Object]](/static/HDFC-new-bbc46138c322f4e8beb5ef76c57a6aff.svg)



 All Tech Blogs
All Tech BlogsEngineering
All Tech Blogs



As we complete three years and begin our fourth, I can’t help but feel proud of the immense success we have achieved with our product – over 150+ million users on our platform have translated into 50+ million daily app sessions, totaling an incredible 500,000 hours on PhonePe each day! The outcome is 10 million daily transactions and 2 Billion data events that help us continuously sharpen the product experience and performance.
All this has been possible only because of the balanced approach we have taken to product development –
Some of this might sound counter-intuitive for a startup in its early years, but when you look at the scale we have achieved – the outlook is not only justified but is probably the only reason we have been able to rise to these heights.
Our approach to engineering has led us to possess perhaps the richest repository of platform capabilities a three year old startup can have. Some examples of these platforms are:
Even the PhonePe mobile app on Android and iOS is architected as a full-fledged ecosystem by itself with clear abstractions. This ensures that core capabilities on the mobile app are common across categories and partner experiences hosted by it.
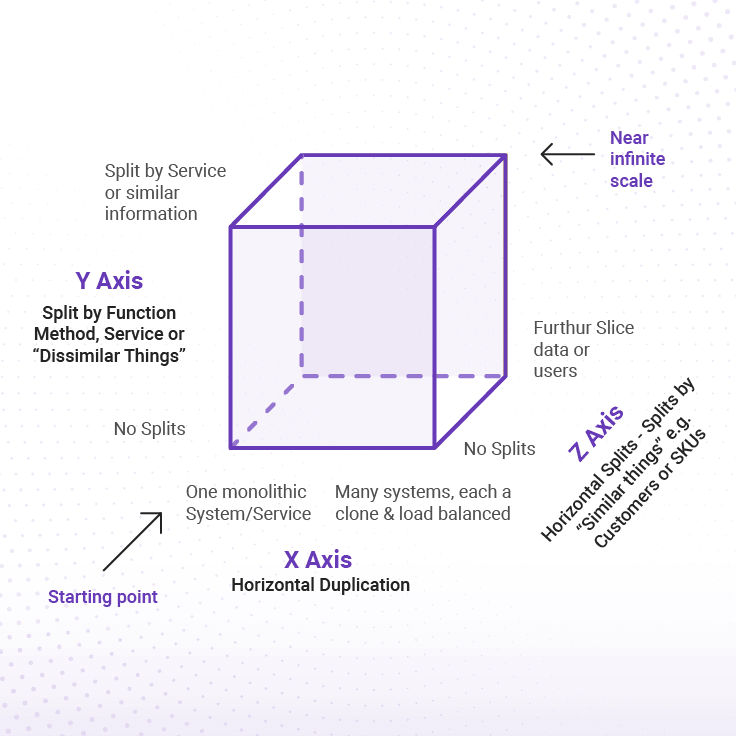
The underlying theme across these systems is that they have all been designed for hypergrowth, helping us scale the product well beyond our plans (an immense luxury and blessing for a rocketship startup). This has been possible because of the early decision to anchor our system architecture on the Scale Cube model, made famous by the book, The Art of Scalability.
Almost all companies today have bought into the X-Axis of horizontal scalability of their code, especially with public cloud bringing in the tools to easily manage deployment at scale. Many have also adopted the Y-Axis and either started with, or quickly moved onto a micro-services architecture on the back-end. But most of the companies have not taken the Z-Axis into account, which ultimately becomes the lynchpin for scalability and performance. The Z-Axis brings the balance of data partitioning and data growth to horizontal scaling of microservices. We have anchored this from Day one, and I believe that is the reason we have seen a lot of success as well as early learning into managing data at scale.
What has also helped us along the way is the fact that the team has come up with a core set of design principles that we always try to adhere to. Anchoring these design choices for core platforms as early as possible has led to consistency in our design and development of critical sub-systems. Here are some of the design principles we follow:
Finally, everything we do starts as an engineering problem of designing for scale for millions of users. Thanks to our awesome engineering team and the amazing work they have been doing – it is with great pride that I announce the launch of the new PhonePe Engineering Blog. Along with solid experience of having built some of the most scalable distributed systems in the industry, the team utilizes the raw talent of the smartest entering the software engineering workforce, bringing a lot of energy to the floor. This helps us move fast while ensuring we are not piling up too much tech debt.
We hope to share in greater depth, how we have approached solving some of the problems we have chosen to take on, and take a deep dive into the design thinking behind building those systems.
Stay tuned for more insights into how Engineering@PhonePe continues to power tens of millions of transactions across India everyday!