![[object Object]](/static/SBI-new-3f05b8e8a65d5a738bcbf2b4b08ae8c3.svg)
![[object Object]](/static/HDFC-new-bbc46138c322f4e8beb5ef76c57a6aff.svg)



 All Tech Blogs
All Tech BlogsArchitecture
All Tech Blogs



In chapter 1, we explored TStore’s functionalities like high-velocity ingestion, efficient reads, and flexible querying, its core concepts like Entities, Units, and Views and finally components like the Client Bundle, Schema Registry, Entity Ingestor and Feed Service. In this chapter we will dive deep into TStore’s architecture, explaining its datastores (HBase and Elasticsearch), message queues (Kafka and RabbitMQ), disaster recovery strategy (Active-Active clusters with data replication), and security measures (Views and IAM).
TStore embraces a polyglot persistence approach, where different databases are strategically chosen for their strengths. While HBase is the primary source of truth for transaction data, it seamlessly incorporates Elasticsearch when complex aggregations are needed.
HBase rocks both read and write speeds, thanks to its clever data storage. It writes fast by appending new data to WAL (disk) and MemStore (in-memory), minimizing disk writes. Bloom filters help with quick “row exists” checks, speeding up reads when new units get created. Hundreds of region servers on top of large colocated HDFS fleets in each cluster handle the data, boosting availability and performance. Since the majority of our reads target recently written units within a few milliseconds, HBase’s in-memory MemStore reads outperforms traditional B-Tree based DBs. HBase prioritizes checking the MemStore first, which offers significantly faster access compared to disk-based storage. This significantly reduces read latency for recently updated units. Even if the data isn’t in the MemStore, HBase’s indexed storage format (SSTables) is optimized for sequential reads. This means when recent data spills over from MemStore to SSTables, retrieving it from these efficiently organized files is still faster than random disk seeks. Adding to the performance boost, an optimized block cache with high hit ratio keeps frequently accessed data blocks from SSTables into memory. Lastly, our compaction strategies fine-tune read/write balance for our specific needs. In short, HBase stood out to be a write-friendly NoSQL database with impressive read performance too!
While HBase excels in specific areas like granular control and write throughput given our in-house expertise for managing Hadoop infrastructure, Azure CosmosDB presents itself as a fully managed compelling alternative, excelling in real-time reads and writes. The current TStore implementation is compatible with both datastores and might be extended to other potential data stores in future.
When it comes to searching and analyzing vast amounts of data, Elasticsearch reigns supreme. TStore leverages Lucene’s powerful search capabilities and aggregation frameworks to enable efficient retrieval and aggregation of specific transaction details based on various criteria. Its sharded architecture across hundreds of data and coordinating nodes in each cluster speeds up even complex queries over TBs of data, while aggregations offer (near) real-time insights like total daily sales for a merchant over millions of transactions.
This distributed streaming platform acts as the data pipeline, efficiently transporting entities across different loosely coupled components of the TStore ecosystem. The Kafka clusters act as the busy courier in TStore, swiftly shuttling transaction events between its different parts and downstreams. It contributes to the asynchronous tasks like data lake backups, payment notification, near real-time search indexing etc. Why async? It frees up TStore’s core for real-time operations while Kafka reliably delivers data in the background, ensuring smooth operations via different consumer components of TStore.
RabbitMQ is the safety net. If Kafka experiences latency or degradation, RabbitMQ steps in as a sideline store. It reliably buffers pending messages until Kafka recovers, ensuring none get lost in the shuffle. In the unlikely event that even retries within RabbitMQ exhausts, the messages are automatically directed to RabbitMQ’s dead letter exchanges (DLX). These messages are then processed separately, allowing for human intervention or alternative handling strategies.
In the high-stakes world of financial transactions, downtime is simply not an option. We at PhonePe understand this responsibility deeply, which is why TStore incorporates a robust Active-Active Business Continuity and Disaster Recovery (BCP/DR) strategy. This ensures uninterrupted transaction processing even in the face of unforeseen disruptions, safeguarding data integrity and minimizing downtime.
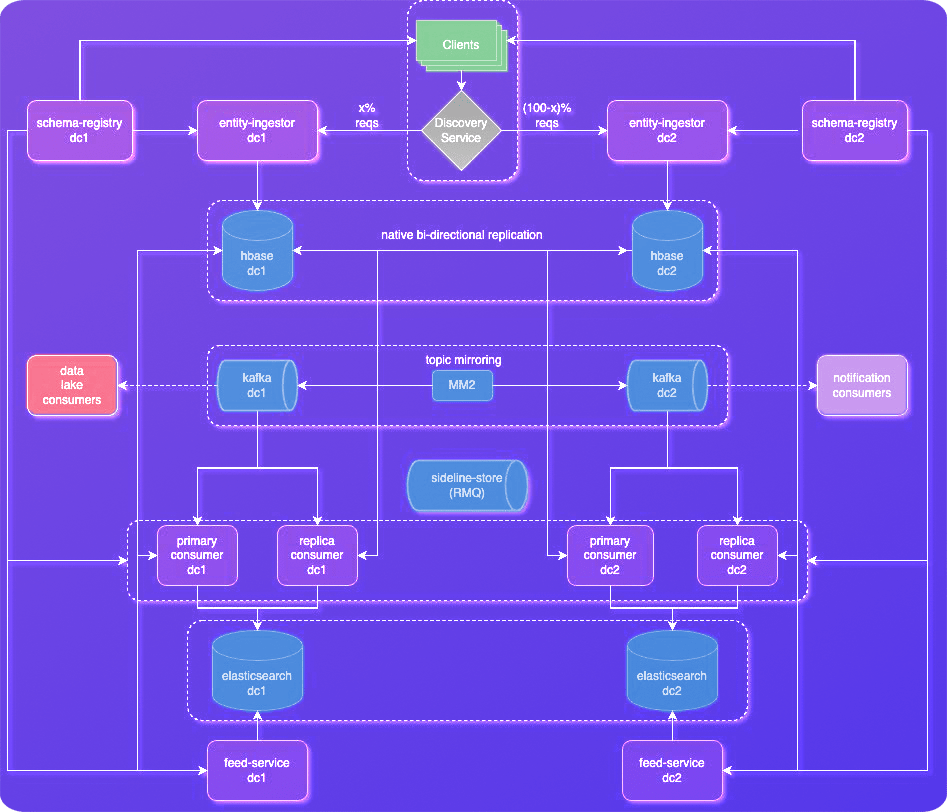
In general, Active-Active configurations are favored over Active-Passive due to their superior resource utilization, enhanced fault tolerance, and concurrent processing capabilities, ensuring optimal performance and resilience. TStore leverages geographically distinct Active-Active clusters, essentially running two independent instances of the entire system in separate data centers. Both clusters handle read and write requests concurrently, eliminating single points of failure and guaranteeing service continuity. This design ensures the following.
To maintain data consistency across both clusters, TStore employs various multi-leader data replication and mirroring mechanisms.
TStore leverages HBase’s built-in bi-directional replication, ensuring synchronization between clusters. Every write operation performed on one cluster triggers a replication stream to the other, guaranteeing identical data states in both locations. HBase writes updates to its Write-Ahead Log (WAL) before committing them to the Memstore. Replication pulls these WAL entries within the replication scope, replicating the exact sequence of changes across clusters. This ensures even writes in progress in one cluster are eventually applied on the other side with minimal latency.
Each data center has its own dedicated Kafka cluster, acting as the real-time messaging backbone. MirrorMaker 2 (MM2) plays a crucial role in mirroring these Kafka clusters. It continuously streams data topics from one cluster to the other, ensuring both clusters have identical, in-sync topics. This mirroring provides both read and write consistency across clusters. Any read operation will access the latest data, regardless of which cluster it’s directed to. Similarly, writes are replicated to both clusters, maintaining data integrity even if one cluster experiences degradation. MM2 offers advanced features like topic filtering, transformation, and offset management for flexible and efficient data mirroring.
The TStore client plays a crucial role in directing traffic and maintaining data consistency within the Active-Active setup.
Based on dynamic configuration in the Discovery Service powered by a central Zookeeper cluster, the client routes writes to the appropriate cluster, balancing load and optimizing performance.
To prevent inconsistencies, the client pins related updates together, ensuring they are always processed within the same cluster, regardless of individual request arrival times.
In the event of a data center outage, TStore leverages manual intervention through its Admin APIs. These APIs offer fine-grained control over traffic shaping and updates the discovery service. In the event of a data center outage or performance degradation, we can readjust the request split and steer requests towards available and the healthy cluster prioritizing performance and business continuity. Manual intervention adds a layer of human oversight and control, enabling responses to specific failure scenarios. It’s important to note that TStore is continually evolving, and future iterations might explore incorporating automated intelligent failover features to complement manual control.
TStore prioritizes user privacy and data security from the ground up via the following approaches.
While discussing the core terminologies, we introduced Views which allow clients access only the specific fields they need within a unit. Similar to relational database views, Views operate on top of existing Unit data (all entities associated with a transaction). They act as a filter, allowing clients to selectively choose specific fields across various entities within a single Unit. This ensures clients receive only the data relevant to their specific needs. Views are dynamically computed on-demand at the Unit level in the read path. Apart from fine-grained data access, views also minimize the amount of data transferred between TStore and clients, improving network efficiency. This ensures that clients never receive Personally Identifiable Information (PII) or any other data not relevant to their role. Client admins can define various views, for their specific needs of different user groups. For example, a merchant view might only expose entities like MERCHANT_PAYMENT and RECEIVED_PAYMENT while a consumer view might display SENT_PAYMENT and other relevant details.
PhonePe leverages a robust in-house IAM platform to define tenancy, roles and permissions for different applications. TStore APIs reinforce security via this IAM platform. TStore APIs have dedicated permissions which are further abstracted via roles for different tenants.
As we conclude our exploration of TStore, its intricate workings have revealed commitment to high availability, resilience, and scalability, ensuring seamless transaction processing even amidst demanding workloads and unforeseen challenges. As new requirements emerge and transaction volumes continue to grow, we’ll tirelessly enhance its capabilities, paving the way for an even more efficient, reliable, and secure future of transactions.