![[object Object]](/static/SBI-new-3f05b8e8a65d5a738bcbf2b4b08ae8c3.svg)
![[object Object]](/static/HDFC-new-bbc46138c322f4e8beb5ef76c57a6aff.svg)



 All Tech Blogs
All Tech BlogsArchitecture
All Tech Blogs



Have you ever had an alarm fail to wake you up, causing a ripple effect of chaos in your morning? At PhonePe, we understand the criticality of such ‘alarms’ in our digital ecosystem.
Take, for instance, our daily Merchant Settlements process. A merchant receives multiple transactions during the day. At the end of the day, we want to ensure the final amount gets credited to their account. A potential delay in this routine job being executed means a merchant not receiving their earnings on time, shaking their trust as a PhonePe Customer.
Or consider digital coupons at PhonePe. Each coupon, with its expiry ticking away, relies on a precise moment to become invalid. Multiply this by millions of coupons, and the magnitude of the task becomes clear. This necessitates a platform that can reliably schedule tasks to invalidate countless coupons with clockwork precision.
In this post, we will take a look at the internals of Clockwork – the system that powers job scheduling across various teams at PhonePe.
At PhonePe, we face the colossal task of managing over 2 billion daily callbacks. The ability to handle over 100,000 job schedules per second with single-digit millisecond latency is not just a goal; it’s a necessity. At p99, our system ensures that there’s no lag in job execution, which in the worst case is capped at 1 minute. Follow along to learn how we’ve made this possible.
A straightforward solution would have been to use embedded schedulers, which are scheduler services that run within the client application, enabling the scheduling of future jobs.
However, this presents a set of challenges, notably the lack of fault tolerance. Imagine the repercussions if the client application crashes, jeopardizing all scheduled jobs. To solve this, we need persistence, but it needs a lot of complex coordination across hundreds of stateless containers. Why? Because in most cases, we would not want the same job to be executed by multiple containers. Then there is the issue of scale – we can have situations where hundreds of millions of such tasks can be triggered in the span of a few hours, resulting in millions of notifications being generated at constant rates & spamming users.
To ensure coordination amongst containers, we would have to employ complicated strategies like partitioning of jobs and leader-election amongst task executor instances in all services handling these kinds of use cases. While possible, this would add a lot of complexity to the service containers themselves, making Garbage Collection, Thread pool, and Auto-scaler tuning extremely difficult due to all containers doing mixed workloads, and adding significantly to the storage layer requirements for them.
With our core organisation value of ‘Simplicity Breeds Scalability’ in mind, we adhere to a design principle of keeping individual systems simple and building up complexity in layers, similar to building complex command chains by piping simple commands on Unix or GNU/Linux.
Inspired by this principle and the widespread requirement across various systems, we developed a centralised platform. This platform – Clockwork, enables clients to easily onboard and schedule future jobs without the need for heavy lifting on their own.
Clockwork is a Distributed, Durable, and Fault-Tolerant Task Scheduler. Let’s dissect what makes it tick!
Whenever a client schedules jobs, we store the job details in HBase and immediately send an acknowledgement back to the client.
Asynchronously, Clockwork keeps on performing HBase scans to find the list of eligible jobs that need execution. Once found, those jobs are immediately pushed to RabbitMQ (RMQ) to avoid blocking the scanner threads. As the callback is an HTTP callback to a URL endpoint, it can be time-consuming, hence it’s important to decouple the job execution from the job extraction. Actual callbacks to the clients are performed in different threads after extracting the Job from RMQ.
Worker threads subscribe to client-specific queues on RabbitMQ. In case of new messages, they are notified. Upon notification, a callback is made to the client as per the job details present in the message. If the callback is successful, an acknowledgement is sent to the RMQ which removes the message from the queue (acks the message). In case of a failure during callback (either because the downstream is down or an unexpected response code was received), retries are performed based on client-specific configuration.
HBase is a key-value store structured as a sparse, distributed, persistent, multidimensional sorted map. This means that each cell is indexed by a RowKey, ColumnKey, and timestamp. Additionally, the rows are sorted by row keys. This allows us to efficiently query for rows by a specific key and run scans based on a start/stop key. It’s like the meticulous librarian, efficiently organizing and retrieving job data. We rely heavily on scans to find the candidate set of jobs whose scheduled execution time is less than or equal to the current time and callbacks are to be sent for.
RabbitMQ is a messaging broker – an intermediary for messaging. It gives applications a common platform to send/receive messages and provides a durable place to store messages until consumed. Consider it the diligent postman, ensuring messages are delivered accurately and on time.
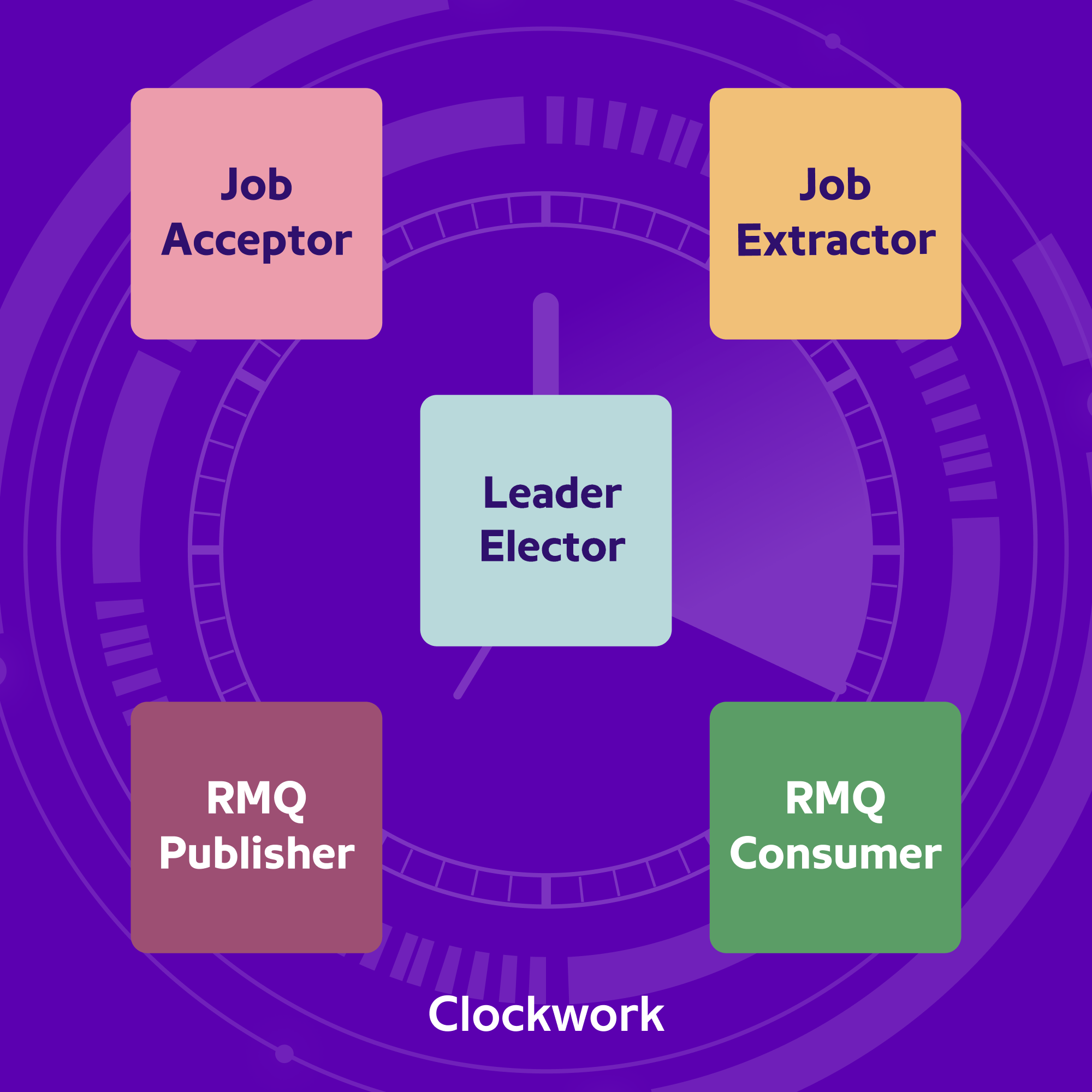
Clockwork service can be divided into 5 modules, each dedicated to performing a single responsibility.
Job Acceptor is a Client Facing Module. Its responsibility is to accept and validate incoming client requests, persist the job details in HBase, and return an acknowledgement to the client. While persisting job details, a random Partition ID is assigned to the Job ID. We will cover the role of partitions in the subsequent sections.
The Job Extractor’s responsibility is to find jobs that are eligible for execution. If the scheduled execution time of a job <= current time, a job becomes eligible. It finds eligible plans by running an HBase scan query between a time range. Once an eligible plan is found, the plans are pushed to RMQ one by one (without waiting for the job execution) to perform the next scan as soon as possible.
At any given moment, multiple Clockwork instances are running. Each instance runs job extractors for all clients as all our containers are stateless. This poses a problem – if all the extractors attempt to identify eligible jobs for the same client simultaneously, they will retrieve the same data, leading to potential duplicate executions of the same job—a situation that must be avoided at all costs. The leader elector’s responsibility is to assign a leader amongst multiple clockwork instances for every client. The leader for a client assigns the partitions to the workers (extractors) running across different instances of clockwork.
If you are still reading this article (kudos), you must have heard about the term Partition ID mentioned earlier. Why is it required? To support clients that need a lot of concurrent callbacks. Partitioning allows us to increase the number of concurrent scans that can be performed while ensuring a job only comes up in a single scan. If we have 64 partitions, we can perform 64 concurrent scans, allowing a higher rate of throughput.
But with great power comes great responsibility! We still have to ensure that no two instances scan the same partition. Otherwise, it will lead to double execution of the same job! This is where the partition assignment comes into the picture. The leader instance is responsible for assigning partitions to the workers – in a round-robin manner. This ensures fairness in partition distribution and ensures no two workers read the same partition.
Once the list of eligible plans is fetched and some validations are performed, the messages are pushed to RMQ which acts as our message broker. While publishing the message we use Rate limiter.
Rate Limiter ensures that we don’t publish more than what we can consume – otherwise, it can lead to the instability of the RMQ cluster – because of a huge backlog of messages. This is achieved by dynamically pausing scans if the queue size goes to a certain configurable threshold. Once the client can receive callbacks, and the queue size starts reducing, subsequent scans start pushing data into the queues.
A lot of our workflows are time-sensitive, and delayed callbacks are sometimes not useful. Clockwork provides a way for clients to specify this time limit by setting a relevancy window. If the client is slow in accepting callbacks (slow consumer problem) or the scans were paused/slow during a time interval (slow publisher problem), expired callbacks will not be sent even when the system stabilizes. Besides this, we also support callback sidelining. This provides a way for clients to avoid getting overwhelmed by clockwork callbacks right after they recover.
It listens to the incoming messages in the RMQ Queues and executes them by making an HTTP call to the specific URL endpoint. Any failure while making the call is handled by client-specific retry strategies.
Some clients don’t want to retry and just want to drop failed messages, whereas some want to perform retries based on exponential backoff with random jitter. In case the retries are exhausted and the callback still fails, the message is pushed to a Dead-Letter-Queue. It’s kept there until the messages are moved back to the main queue or the messages expire.
In the vast narrative of PhonePe, Clockwork plays a pivotal role. Clockwork’s architecture is tailored and scaled to our specific needs and has enabled us to manage the enormous volume of tasks that need to be handled efficiently. This system allows us to offer our customers seamless and uninterrupted service.
As engineers, we know that growth comes with challenges to infrastructure and system quality. At PhonePe, we are constantly seeking solutions to maintain that quality while managing costs and accommodating ever-increasing surges in traffic. As we continue to grow and face new challenges, Clockwork will be there, ticking away, ensuring every ‘alarm’ goes off just as planned.
Our goal is to share our learnings with the larger engineering community so that we can all learn how to address the challenges of growth and adapt our systems
For those intrigued by the challenges we tackle and our approach to technology, we invite you to explore career opportunities with us at PhonePe Careers.